🌶️ Load Balancing ≠Reliability 🌶️

Marino is a Canadian, Traveller, International Speaker, Open Source Advocate for Service Mesh, Kubernetes, and Networking. He is an Ambassador @ EddieHub, and Lead Organizer for KubeHuddle Toronto. He is passionate about technology and modern distributed systems. He will always fall back to the patterns of Networking and the ways of the OSI. Community building is his driving force; A modern Jedi Academy.
TL;DR:
Load balancing ≠ Reliability.
Emotional impact of system failures.
It's the system's fault, not the individual's.
Reliability is availability and trust.
Key strategies for system reliability.
Cautious use of AI in operations.
Evolution of disaster recovery to proactive reliability.
Tools like Komodor for Kubernetes reliability.
I've got the SPICE 🌶️🌶️🌶️
While working with Komodor, I had a conversation with some individuals who believe that using load-balancers was solving for their reliability challenges. While partially true, I wanted to expand on this. I was quick to determine that my years in Disaster Recovery could be re-imagined as an internal compass of establishing a strong set of guidelines for continuous reliability... Which eventually transformed into a session at KubeHuddle, KCD New York, and NADOG Toronto.
What happens when things fails?
Our emotions are tied to when something breaks, big or small. I did a quick survey to understand the emotional aspect of an incident. We feel personally tied to, and responsible to the systems we work with, especially the ones we've built.
I recall several times where throughout my career, I've affected production in some way...and it's left me feeling Frustrated - the most valid feeling when an incident occurs and we don't have the means to quickly resolve. In fact, feeling of being personally responsible for an outage can sometimes leave us feeling like a failure.

JUST A REMINDER: IT'S ABSOLUTELY NOT YOU ❤️.
Not the engineer, not the architect, not the individual. It's the system, the software that does the unexpected.
What does Reliability mean to you?
I followed up with another survey to understand the mindset of problem-solvers and ways they work to be far more proactive to prevent disasters.

AVAILABLE - This makes absolute sense. We want systems to be as available as they can be with limited wiggle room for outages, or even maintenance. It's been well defined and well aligned to the concept of several nines, and SLOs/SLAs/SLIs. (LMAO at the no AI gibberish... because while true, hold that thought for a second)
TRUST - This one caught me off-guard because what the hell does trust have ANYTHING to do with reliability? After some reflection, there are a few ways to interpret this.
The way systems and services trust each other. Some form of AuthN.
Trusting our systems to do the right thing, always. This one is exceedingly hard to achieve because to trust our systems, we have to trust those who built these. But simultaneously not blame them for when things go wrong.
What does reliability mean to me?
Having spent a significant amount of time in the Disaster Recovery world, working through capacity planning and various migrations, there were a few key areas that could be addressed to increase reliability in systems.
Right-sized workloads and infrastructure (CPU/MEM) through constant analysis and tuning
Policies to address missing guardrails for unauthorized actions, or access
Reduce service latency by understanding bottlenecks in the network
Reduce tooling and login fatigue with SSO and Short-lived-tokens
Streamlined proactive maintenance, capacity and capability planning
Strategic MTTR reduction through constant analysis and adjustment of failing workloads and infrastructure
Resilient, reusable and automated infrastructure, load balancers, ultra fast redundant network, and working DNS
Retries, resiliency, and service invocation planning, using tools like an API Gateway or Service Mesh
Platform consolidation for workload metadata, infrastructure metadata, events, logs, and other observability data points

(It's always DNS)
AI in Reliability? Absolutely Not...Well maybe some...
This is not an AI blog post. There millions of those (probably mostly generated by AI), feel free to go read them if you like, however, I'm not going to ignore the obvious. You've likely heard of K8SGPT which opened the door to having a live in-Kubernetes operator that could help you discern things about your environment. This is an ideal approach to leveraging and using AI for operations and reliability in Kubernetes. I do believe it's fine to pair some LLMs with prompts to comb through logs, or events, or other observability data to speed up that resolution process. I also believe it should be scoped and limited as well.
Reliable Kubernetes? Yes, Please!
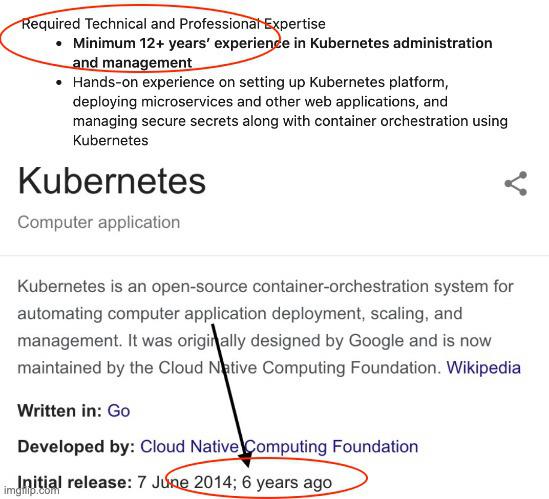
There are many ways to run workloads. There are many ways to deploy and run Kubernetes. I mean, Kubernetes is almost 10 YEARS OLD 🤯🤩😎
OH HEY, we're getting so close to meeting those job requirements! 🎉
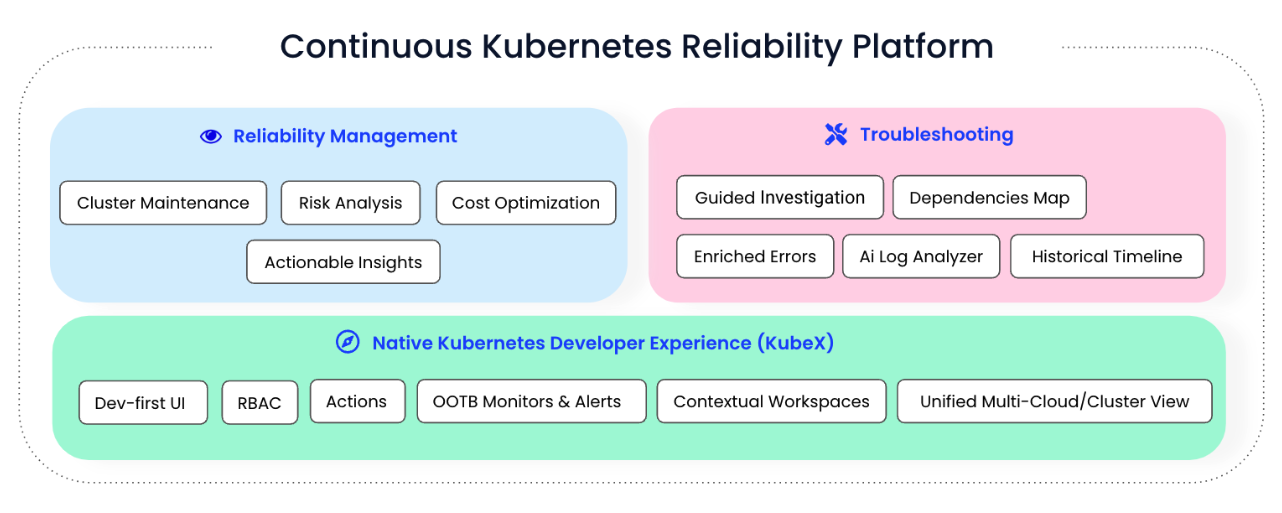
We are however, at an inflection point with many tools that address these aspects individually:
Cost
Operations
Troubleshooting
Policies
Security
Proactive reliability
Consolidating these into a fewer set of platforms works to reduce that cognitive load and ultimately addresses that frustrated feeling we get when things fail. You absolutely need to check out Komodor if this sounds like you.
Interested in the full presentation? Here you go!
To conclude, there's plenty to consider w.r.t. reliability. It's emotions combined with systems we have limited influence over and can do unexpected breaking things.
I'm always happy to chat about Disaster Recovery and what it morphed into over the years. Feel free to reach out on Twitter or Linkedin!
Cheers and thanks for reading 😊!



